

Pod tym pojęciem rozumieć należy działanie z zakresu DSP (Digital Signal Processing), które zrównuje częstości wymuszające (w naszym przypadku jest to prędkość obrotowa) do jednej wartości np 10 Hz – taka wartość została przyjęta w poniższym przykładzie. Dane przygotowane w ten sposób zostały użyte do treningu modelu sztucznej inteligencji.
 |
 |
 |
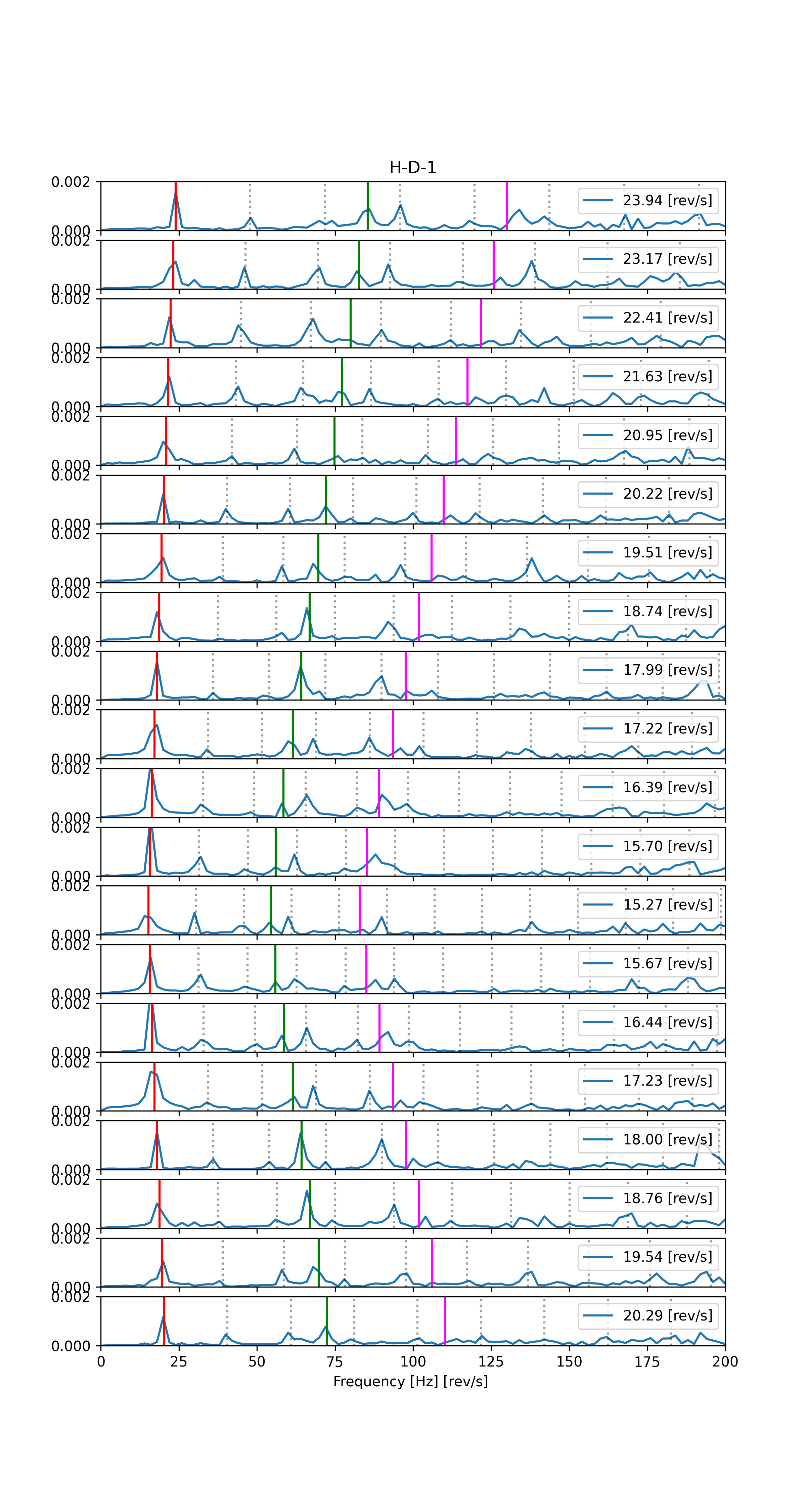 |
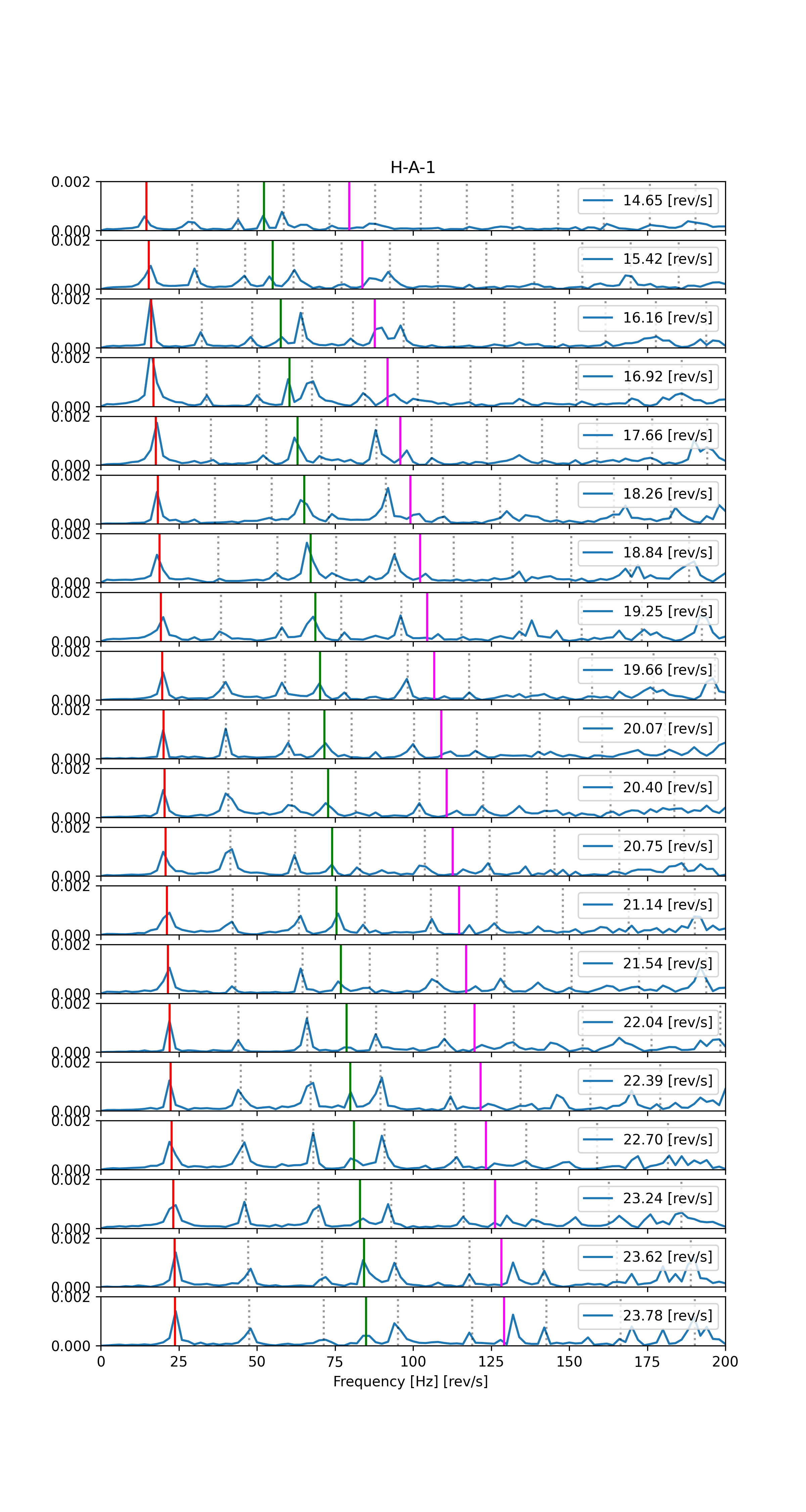
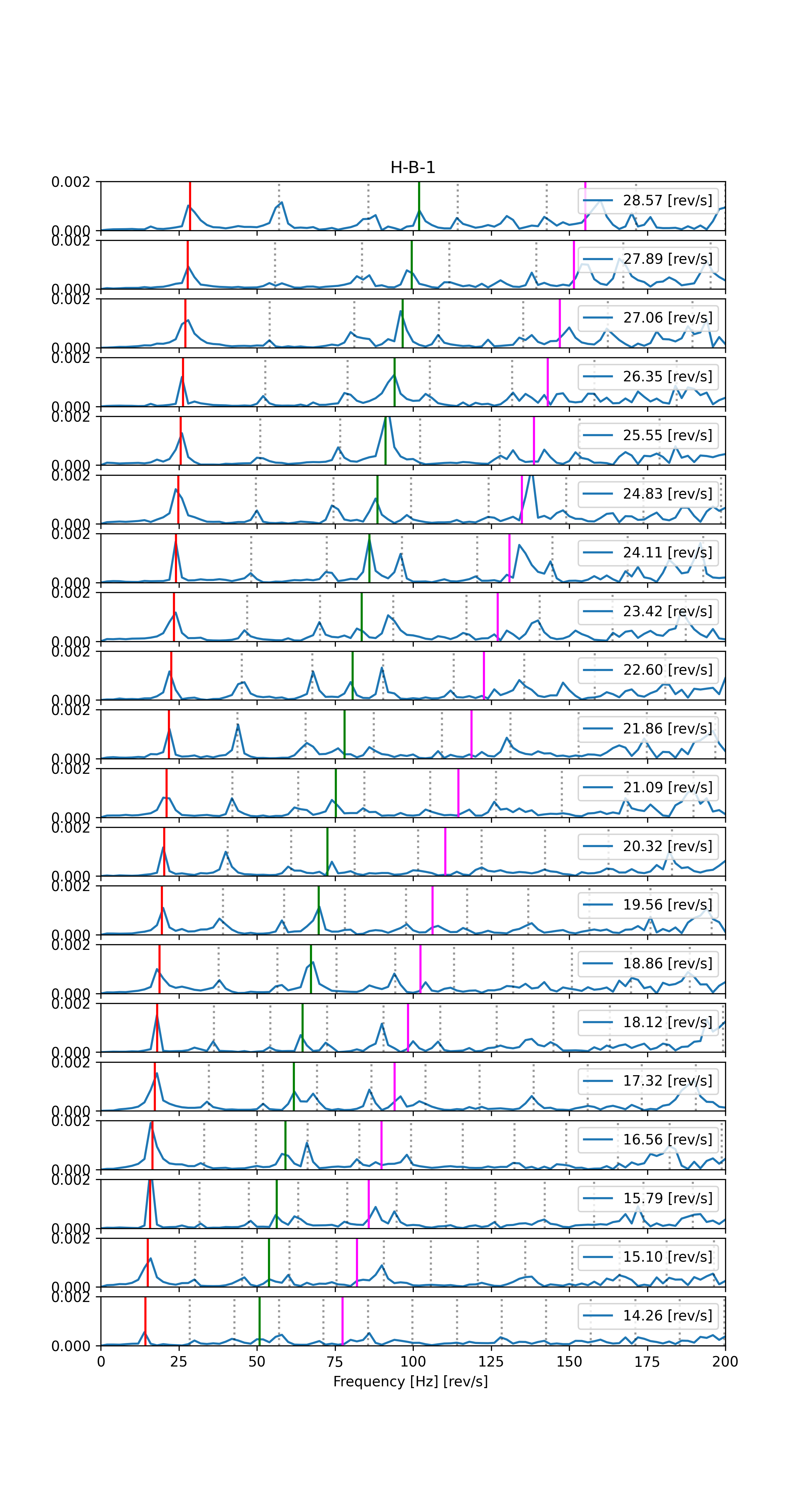
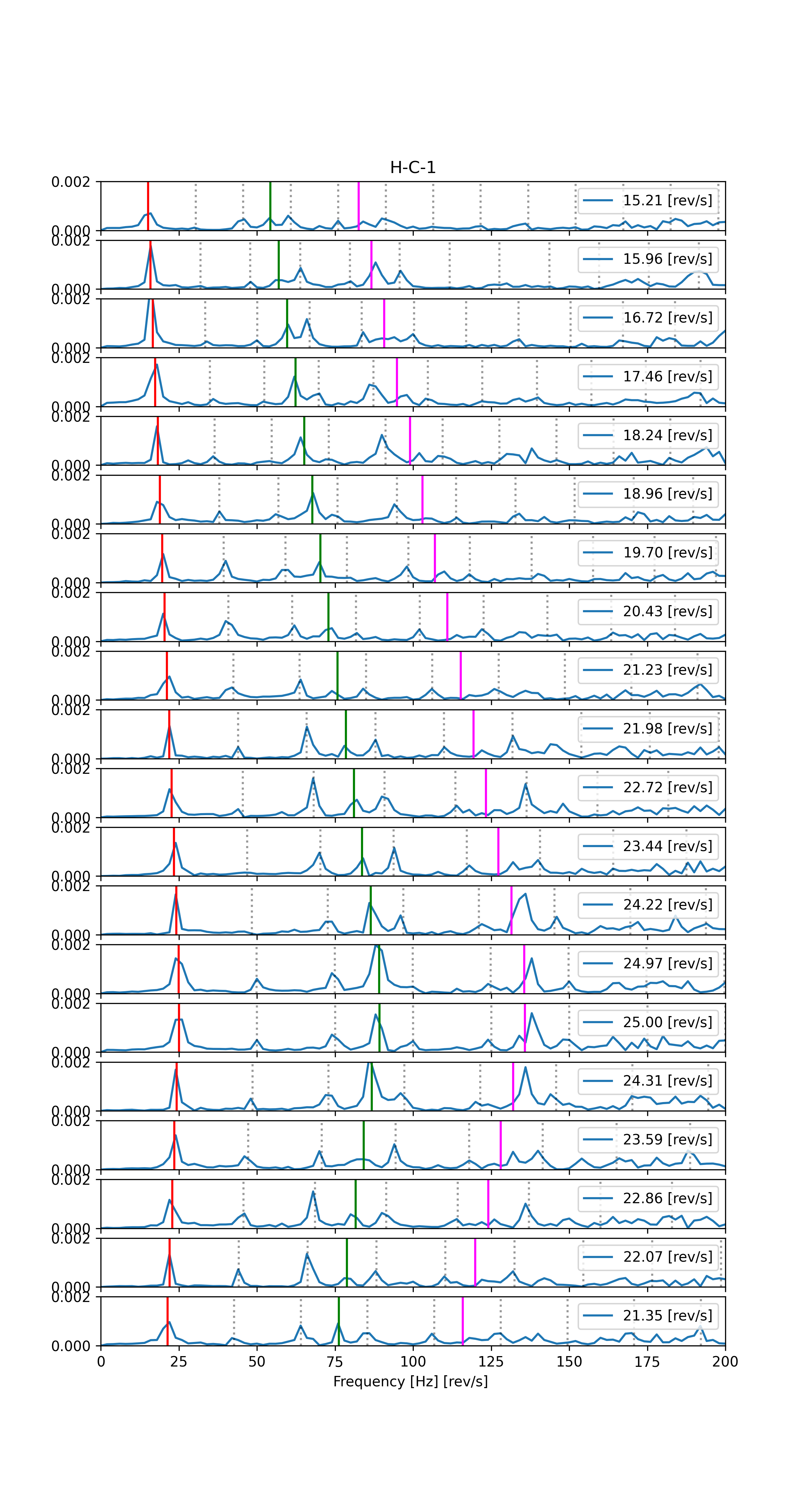
Rys. 3. Zestaw widm częstotliwościowych otrzymanych z podzielonych sygnałów.
W powyższym przykładzie użyty został model z dziedziny ML (Machine Learning), akademicką dyskusją pozostaje kwestia czy ML nadal zaliczane jest jako AI, wg wielu definicji samej sztucznej inteligencji ML jak najbardziej się w niej mieści. Nadal są to algorytmy wymagające uczenia choć działają w sposób odmienny niż algorytmy oparte na sieciach neuronowych ANN (Artificial Neural Network) zaliczające się z kolei do dziedziny DL (Deep Learning) chociaż to ich wielkość, a raczej głębokość o tym świadczy. Przyjmuje się że dopiero modele o strukturze zawierające powyżej 3 warstw można nazywać modelami głębokiego uczenia.
W naszym przypadku został użyty model typu SVM (Support Vector Machine), a w szczególności SVC (Support Vector Classifier) jako model klasyfikacyjny. Jego zadaniem jest zakwalifikowanie danej próbki sygnału zawierającego odczyty amplitudy przyspieszeń do kategorii (klasy). W naszym przypadku będzie to [sprawne, uszkodzenie_typ1, uszkodzenie_typ2, uszkodzenie_typ3].
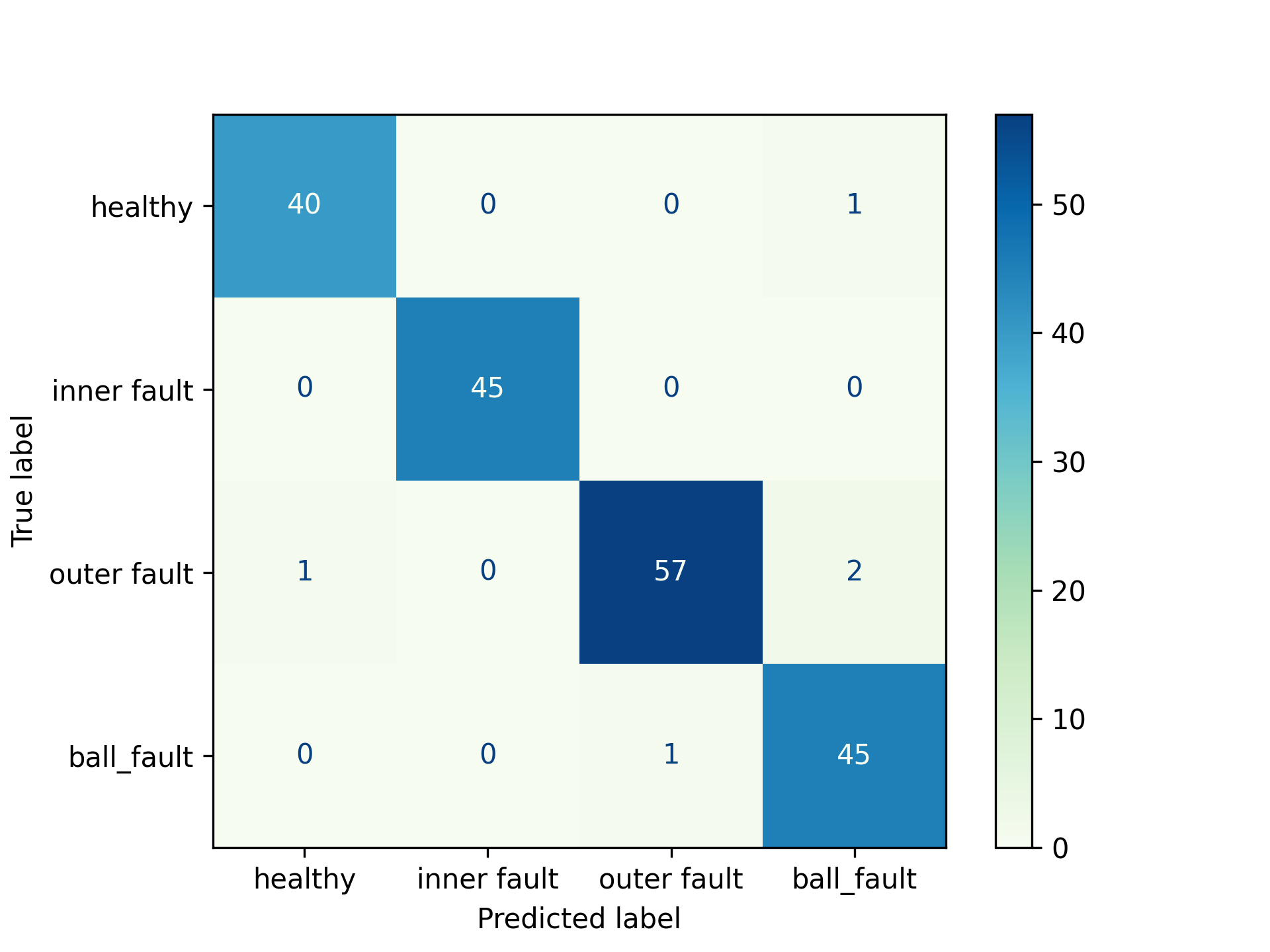
Do oceny sprawności modelu klasyfikacyjnego używa się tzw. metryki dokładności accuracy przyjmującej wartości od 0 do 1, gdzie 0 oznaczać będzie jego zerową skuteczność a wartość 1 stuprocentową. Jedną z metod wizualizacji sprawności modelu jest confusion matrix, nazywana w języku ojczystym macierzą konfuzji, chociaż lepiej brzmiącym tłumaczeniem wydaje się macierz pomyłek przedstawiona na (Rys.4). Którą należy interpretować w następujący sposób – poziome rzędy oznaczone są jako True label, czyli stany rzeczywiste, Predicted label to wartości oszacowane przez model. Wartość 40 w lewym górnym rogu oznacza że 40 próbek sygnału pochodzących z nieuszkodzonego łożyska (healthy) True label – zostały poprawnie oznaczone przez model jako nieuszkodzone Predicted label. Wartość 1 w prawym górnym narożniku oznacza, że jeden egzemplarz sygnału pomimo że w rzeczywistości miał etykietę nieuszkodzonego,został błędnie zakwalifikowany jako łożysko z uszkodzonym elementem tocznym (ball fault). I kolejno liczba 2 znajdująca się na skrzyżowaniu outer fault – True label i ball fault – Predicted label oznaczać będzie że dwa sygnały pochodzące z łożyska z uszkodzonym pierścieniem zewnętrznym zostało błędnie zakwalifikowane jako z uszkodzonym elementem tocznym. W uproszczony sposób można powiedzieć, że gdy przekątna macierzy pomyłek biegnąca od lewego górnego rogu do prawego dolnego zawiera największe wartości to model wykazuje się dobrą sprawnością oceny. Wartość podstawowej metryki dla modeli kwalifikacyjnych tzw. dokładność (accuracy) jest wyrażona stosunkiem ilości wszystkich przypadków do tych poprawnie wytypowanych. Dla naszego przypadku wynosi ona 98%. Innymi słowy mówiąc na 100 pomiarów 98 zostało oznaczonych poprawnie a 2 błędnie.
Powyższe rozważania dotyczą jedynie jednego łożyska z publicznie dostępnych danych pobranych z internetu. Pomiary zostały wykonane za pomocą sprzętu laboratoryjnego z odizolowanego od czynników zewnętrznych środowiska. Użyty został stosunkowo prosty podstawowy model ML – SVC. Istnieje cała gama innych modeli które mogłyby dać równie dobre wyniki. Do zadań tego typu można również zaprzęgnąć sieci neuronowe ANN z tzw warstwą konwolucyjną do których zbędne byłoby użycie transformaty Fouriera FFT. Podsumowując, możliwości w sposobie podejścia do tematu detekcji uszkodzeń łożysk tocznych jest wiele. Jednakowoż wynik 98% jest bardzo dobry i dobrze rokuje dla tej metody.Do powyższej analizy zostały użyte ogólnodostępne biblioteki języka Python takie jak: Numpy, Scikit-learn oraz SciPy. Wykorzystywany komputer to zwykły laptop o niewyśrubowanych parametrach. O ile processing danych zajmuje około kilkudziesięciu sekund, tak proces treningu i samej predykcji trwa relatywnie krótko, po wciśnięciu entera wynik pojawia się natychmiast. Co świadczy, że do wykonania takich analiz nie są wymagane kosztowne moce obliczeniowe w postaci sprzętu a oprogramowanie jest praktycznie darmowe.
Przykład ten ma raczej na celu przedstawienia pewnych możliwości zastosowania sztucznej inteligencji w wykrywaniu potencjalnych zjawisk. Nie koniecznie muszą to być łożyska, w rzeczywistości mogą to być dowolne inne sygnały które można zamienić do postaci cyfrowej (zdigitalizować) takie jak wartości pobieranego przez urządzenie prądu, temperatury, odkształcenia, lub dowolnych innych mierzalnych parametrów dla wartości zarówno dyskretnych jak i zakresowych.
Autor: Piotr Kmita – inżynier mechanik, pasjonat zagadnień związanych ze sztuczną inteligencją i jej wykorzystaniu w szeroko rozumianym temacie predictive maintenance, czyli najogólniej mówiąc przewidywaniu serwisu maszyn zanim nastąpi awaria.


























































